Reading Guide & Overview
Smoothquant Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.

For 2026, Smoothquant remains one of the most searched-for profiles.
Below is a handpicked selection of video coverage regarding Smoothquant.


Stay updated on Smoothquant's latest milestones.


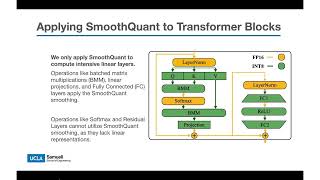
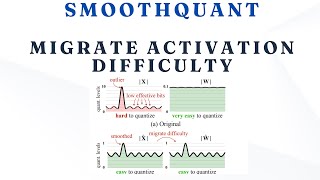
SmoothQuant - Accurate and Efficient Post-Training Quantization for Large Language Models Large language models (LLMs) show excellent performance but are compute- and memory-intensive. Quantization can reduce ... In this video, we look into SmoothQ Algorithm and Paper: Paper: Pseudocode Open Source ... Seminar date : 2024.07.05 # Seminar contents Paper Review Seminar # Paper Title Xiao, Guangxuan, et al. " 00:00 Introduction to LLM Quantization 02:15 What is Quantization? 04:45 Post-Training Quantization (PTQ) vs. QAT 07:30 GPTQ ... Pseudo-lab (-lab ) EfficientLLM study Presenter: 김승우 Date: 2025/09/30 Paper:
Quantization is an excellent technique to compress Large Language Models (LLM) and accelerate their inference. In this video ... Are 1-bit LLMs the future of efficient AI? Or just a catchy Microsoft metaphor? In this video, we break down BitNet, the so-called ... Quantization is an excellent technique to compress Large Language Models (LLM) and accelerate their inference. Following up ... Quantization can unlock huge performance gains for LLM inference - but only if you pick the right format for your workload. In this ... The explosive growth of large language models (LLMs) has facilitated a significant number of breakthroughs in fields like text ...

Explore the primary sources for Smoothquant.
Data is compiled from public records and verified media reports.
Last Updated: June 12, 2026
Disclaimer:








![[IDSL Paper Review] SmoothQuant](https://i0.wp.com/ytimg.googleusercontent.com/vi/FjRJMzqAbgY/mqdefault.jpg?resize=320,180)


![[Paper Review] SmoothQuant](https://i0.wp.com/ytimg.googleusercontent.com/vi/dUzFAydJalM/mqdefault.jpg?resize=320,180)





