Reading Guide & Overview
Cs104 Smoothquant Final Presentation Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.

For 2026, Cs104 Smoothquant Final Presentation remains one of the most searched-for profiles.
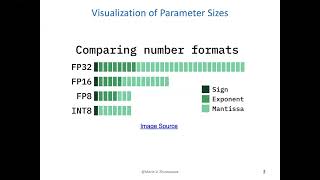
Large language models (LLMs) show excellent performance but are compute- and memory-intensive. Quantization can reduce ... Symmetrization, hashing: linear probing (5-wise indep.), bloom filters, cuckoo hashing, bloomier filters. ISCA'25: The 52nd International Symposium on Computer Architecture Session 7C: Quantum II Session Chair: Huiyang Zhou ... At the Nasscom Agentic AI Confluence 2025, this masterclass at the Developer Track explored how developers can optimize ... Zeta transform, Möbius inversion, streaming algorithms, necessity of randomization and approximation, distinct elements. Lecture recording of Carnegie Mellon University's Spring 2026 Class: 10799 Diffusion & Flow Matching Lecture 6: The Design ...
In this webinar, Ivan Svetunkov, Leonidas Tsaprounis and Filotas Theodosiou explain their work with the project on translation of ... Lecture recording of Carnegie Mellon University's Spring 2026 Class: 10799 Diffusion & Flow Matching Lecture 4: Score-based ... Quant-LLM: Accelerating the Serving of Large Language Models via FP6-Centric Algorithm-System Co-Design on Modern GPUs ...
Below is a handpicked selection of video coverage regarding Cs104 Smoothquant Final Presentation.
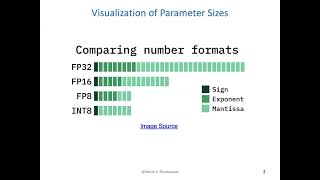
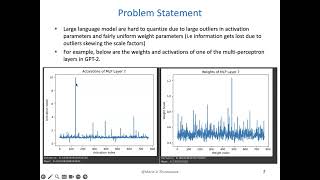



Explore the key sources for Cs104 Smoothquant Final Presentation.
Data is compiled from public records and verified media reports.
Last Updated: June 13, 2026
Stay updated on Cs104 Smoothquant Final Presentation's latest milestones.

Disclaimer:













