Positional Encoding In Transformers Deep Learning Campusx Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Important Facts

Explore the primary sources for Positional Encoding In Transformers Deep Learning Campusx.
Introduction of Positional Encoding In Transformers Deep Learning Campusx

Timestamps: 0:00 Intro 0:42 Problem with Self-attention 2:30 For more information about Stanford's Artificial Intelligence programs visit: This lecture is from the Stanford ... Transformers are a powerful class of models in natural language processing and machine learning, revolutionizing various tasks ... Self Attention works by computing attention scores for each word in a sequence based on its relationship with every other word ... Breaking down how Large Language Models work, visualizing how data flows through. Instead of sponsored ad reads, these ...
Developments
Stay updated on Positional Encoding In Transformers Deep Learning Campusx's newest achievements.

Video Highlights & Reports
Below is a handpicked selection of video coverage regarding Positional Encoding In Transformers Deep Learning Campusx.

Positional Encoding in Transformers | Deep Learning | CampusX

How do Transformer Models keep track of the order of words? Positional Encoding
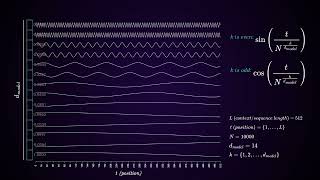
How positional encoding works in transformers?

Lec 16 | Introduction to Transformer: Positional Encoding and Layer Normalization
Full Guide
Data is compiled from public records and verified media reports.
Last Updated: June 18, 2026
Future Outlook

For 2026, Positional Encoding In Transformers Deep Learning Campusx remains one of the most talked-about profiles.
Disclaimer:














