Reading Guide & Overview
Effective Parallelisation For Machine Learning Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Below is a handpicked selection of video coverage regarding Effective Parallelisation For Machine Learning.
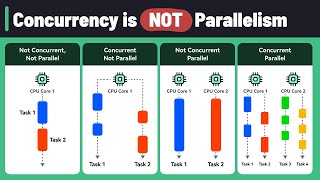
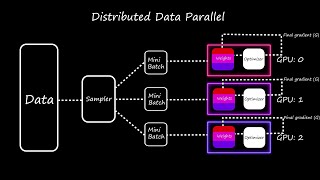


Explore the main sources for Effective Parallelisation For Machine Learning.
Stay updated on Effective Parallelisation For Machine Learning's newest achievements.


For 2026, Effective Parallelisation For Machine Learning remains one of the most searched-for profiles.

Get a Free System Design PDF with 158 pages by subscribing to our weekly newsletter: Animation ... In this talk we present how we trained a 530B parameter language model on a DGX SuperPOD with over 3000 A100 GPUs and a ... Mamba is a new neural network architecture that came out this year, and it performs better than transformers at language ... Check our courses TechNeuron: 200+courses Lifetime Warranty Course url: Full Stack Data ... Do you want to speed up the time that it takes to calculate your This video contains a hands-on example of how to leverage Many Model Step in Azure
This talk dives into the performance details of GPUs and why GPUs are useful for ... my name is junction i'm going to present our recent work past secure ml an
Data is compiled from public records and verified media reports.
Last Updated: June 14, 2026
Disclaimer:


















