Reading Guide & Overview
Mdp Value Iteration Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.

For 2026, Mdp Value Iteration remains one of the most searched-for profiles.
Stay updated on Mdp Value Iteration's latest milestones.


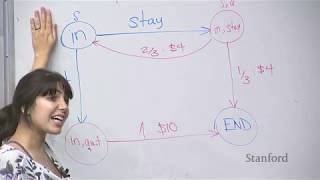
For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: Andrew ... COMPSCI 188, LEC 001 - Fall 2018 COMPSCI 188, LEC 001 - Pieter Abbeel, Daniel Klein Copyright UC Regents; ... In this video, you'll get a comprehensive introduction to Markov Design Processes. Let's talk about the most consequential equation in reinforcement learning: The bellman equation. ABOUT ME ⭕ : ... ... the value of a state is the optimal expected sum of discounted Rewards acting in the
Deterministic route finding isn't enough for the real world - Nick Hawes of the Oxford Robotics Institute takes us through some ...

Explore the main sources for Mdp Value Iteration.
Below is a handpicked selection of video coverage regarding Mdp Value Iteration.



Data is compiled from public records and verified media reports.
Last Updated: June 12, 2026
Disclaimer:












![[UCLA RL-LLM] Chapter 1.1: MDP foundations, imitation learning, and value iteration](https://i0.wp.com/ytimg.googleusercontent.com/vi/R2oT9Tcv0eU/mqdefault.jpg?resize=320,180)




